
背景介绍
自从使用opensips和rtpengine做sbc以来,一直对其所能支撑的并发数有所怀疑,正好最近项目不多,就申请了三台阿里云机器来做压测,共耗时一个月。
本次压测的功能:把opensips用作注册代理转发,现对压测结果做个总结。
压测模型
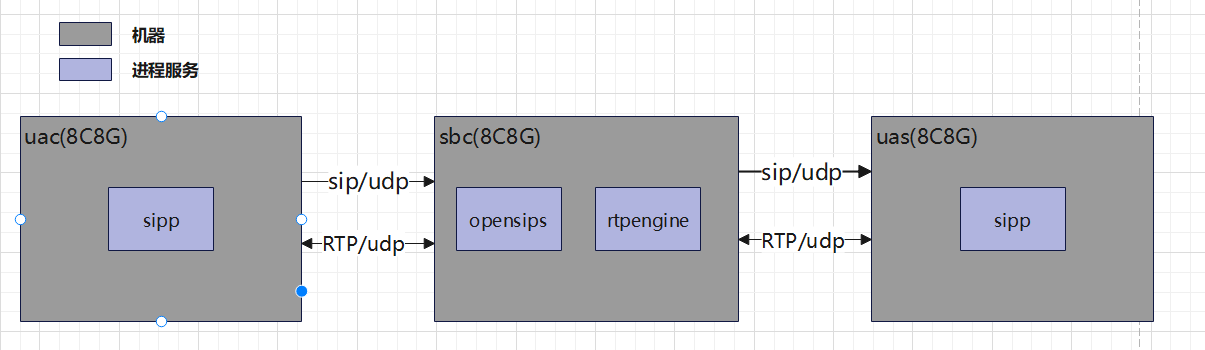
压测场景
坐席A和B使用udp通过opensips注册到uas,坐席A通过opensips拨打电话到坐席B, 坐席B接通电话后,坐席A和B通过opensips进行2分钟通话,然后坐席A挂断电话。
版本信息
|
|
opensips和rtpengine使用docker部署的好处就是使用docker stats 能够获取容器是实际占用内存和cpu使用率
监控指标
|
|
监控工具
|
|
压测注意问题
1. 压测的cps和通话时长要合适
压测目的是保持稳定并发数时的资源使用情况
- 如果通话时长太短比如:1分钟以内,在高并发的情况下(1000往上),无法稳定保持并发数。
- 如果cps太大,此时网络带宽会有比较大的波动,高并发数情况下,opensips和uas会出现丢包情况。
合理的cps计算方式为: 并发数/通话时长(s),如果是小数可以适当向上取整。
比如: 1000并发数,通话时长为2分钟,那么cps为1000/120=8.3约等于9。 对应的sipp 命令为: -r 9 -rp 1s
2. 如何确定总压测时长
压测时长2小时,实际的sipp压测脚本参数并没有总通话时长,但sipp中有总压测数参数,那么应该如何确定压测时长呢?
总压测数=并发数*压测时长(分钟)/通话时长(分钟)
对于此压测场景,总压测数=1000*120/2=60000,对应的sipp命令为: -m 60000
注意:实际压测中并不是并发数1000,sipp的-l 就是1000,可能会比1000多几个,按照实际压测来调整.
3. 完整的uac sipp命令
以1000路为例:
|
|
可以看到-l 1019,如果想要dialog能稳定到1000路,需要把-l参数调整到1019。
压测结果分析
opensips和rtpengine的内存未释放?
在udp压测时,opensips的运行参数为: -m 2048 -M 100 意思为:共享内存为2048MB,pkg内存100MB, udp_workers=32 tcp_workers=8。
在实际压测过程中,阿里云的监控能够看到,内存使用率一直都是2G,变化较少。但是通过docker stats分别在压测开始和结束统计,能够看到opensips和rtpengine的实际占用内存是有变化的。以1000路为例:
opensips:959.4MiB->982MiB | rtpengine: 23.89MiB->87.73MiB
压测停止6小时之后,opensips和rtpengine的docker实际占用内存并没有减少,一开始我以为是内存泄露,调整opensips.cfg添加memdump=2开启内存打印。
在压测结束后, 通过opensips-cli执行mi mem_shm_dump,参考:opensips内存泄漏排查,并没有发现有相似的dumping all alloc'ed. fragments。
而且压测结束后,查看rtpengine的端口占用情况,rtp端口都被释放了。
值得注意的是:并发数减少,opensips和rtpengin的内存占用不会变,并发数增加,它们的内存会往上升。之后一直维持该内存大小不再增加。
个人猜测: opensips和rtpengine的占用内存是动态扩展的,当并发数增加,内存会自动扩展,当并发数减少,占用的内存不会自动释放。
压测极限
监测数据
本次使用的是opensips-cli
|
|
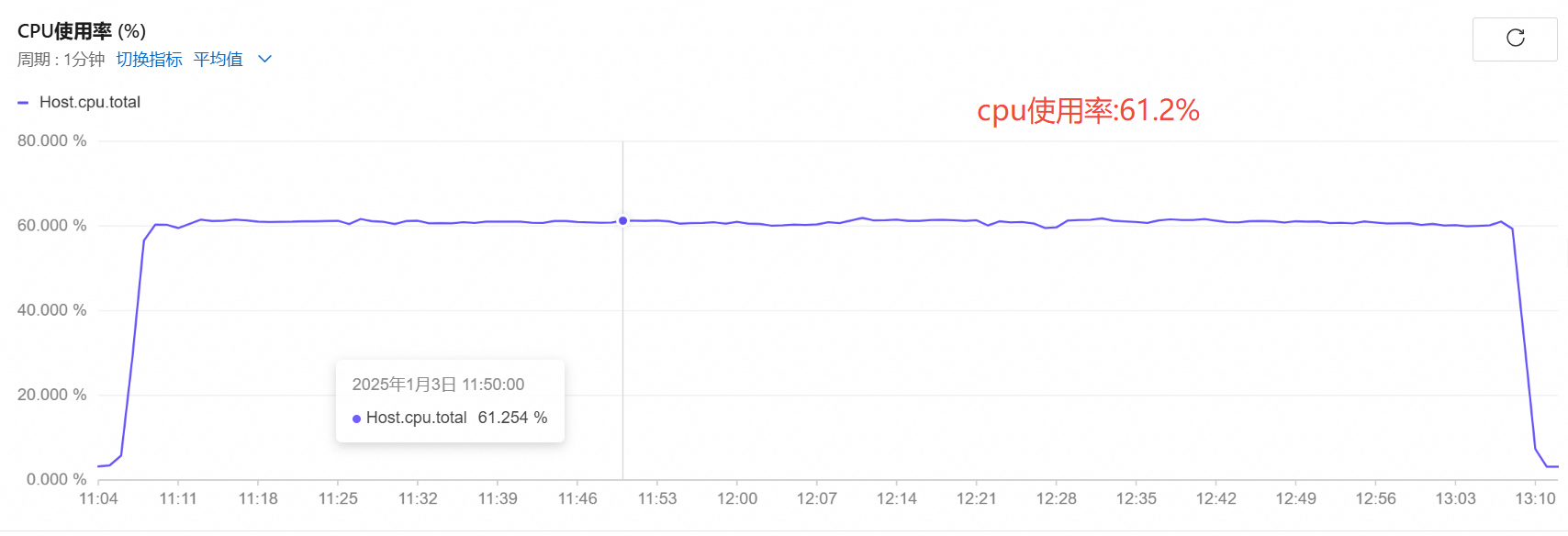
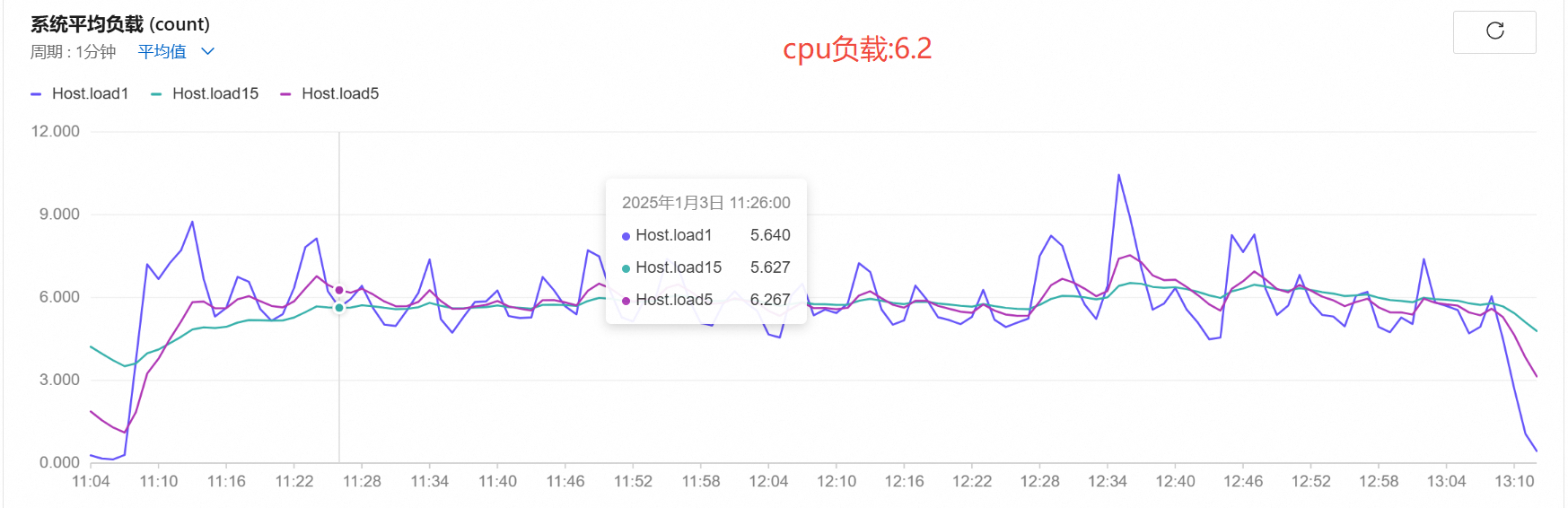
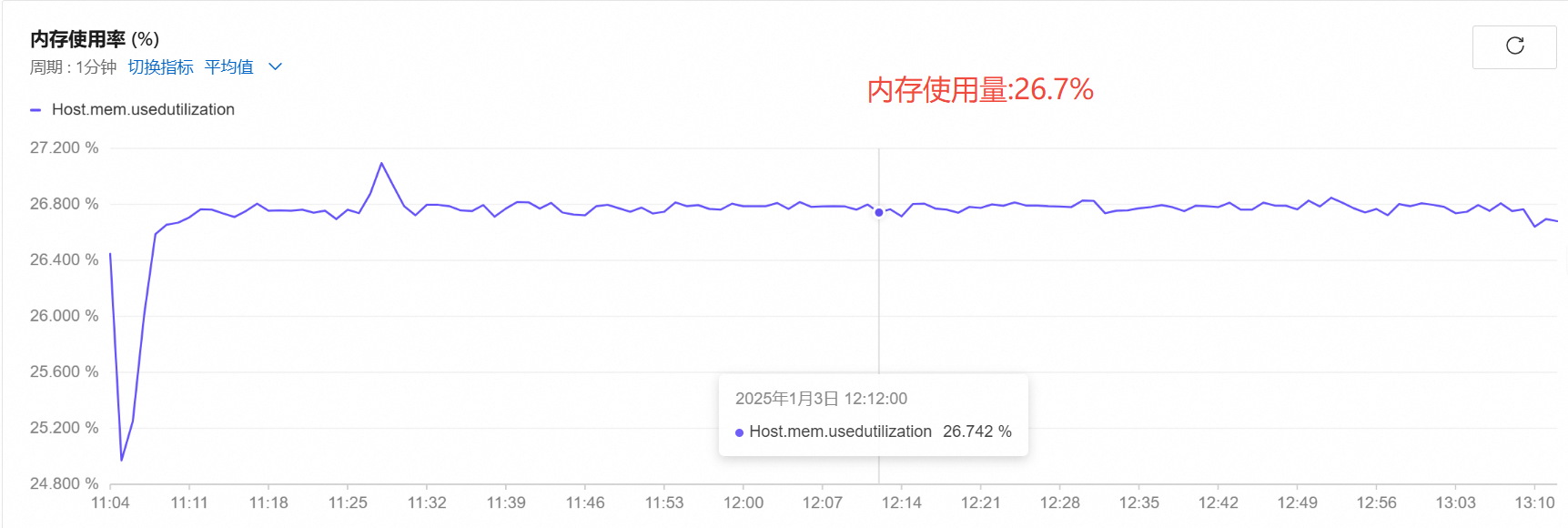
实际压测2小时数据
- 1700路
-
cpu使用率
-
cpu负载
-
内存使用率
-
带宽:
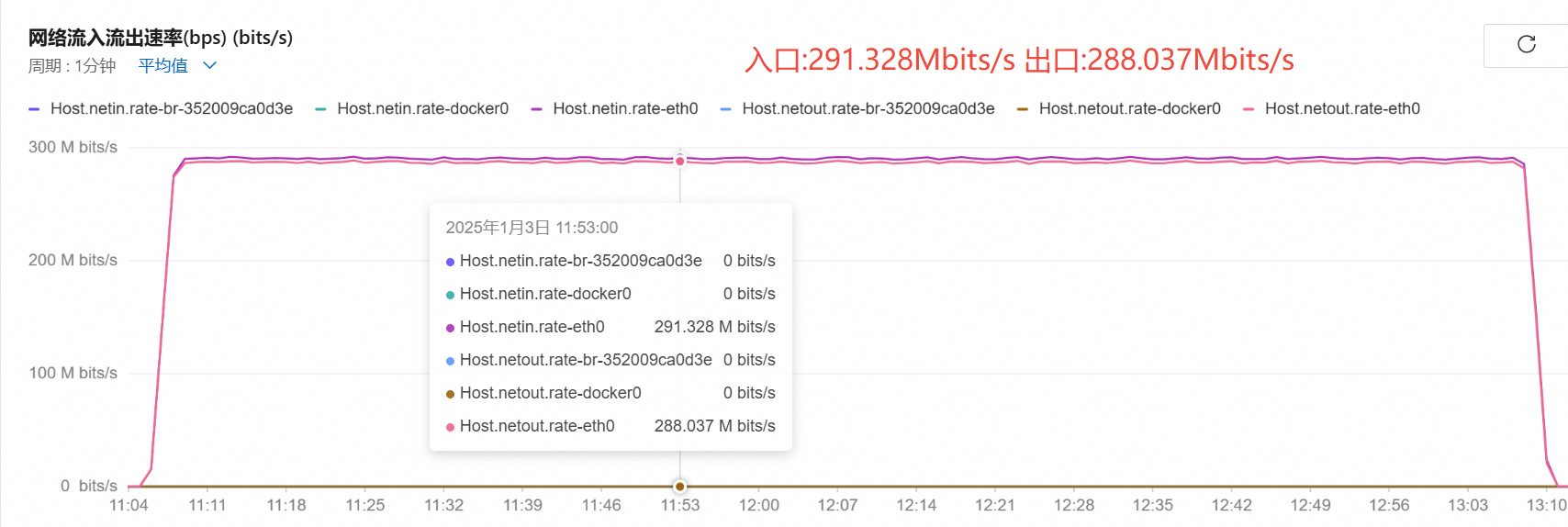
-
通话量:
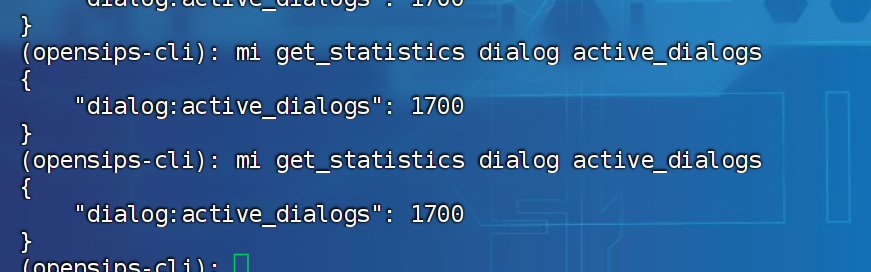
-
内存增长:
opensips:959.4MiB->989MiB=29.6MiB | rtpengine: 24.46MiB->118.9MiB=94.44MiB
- 1800路
-
cpu使用率
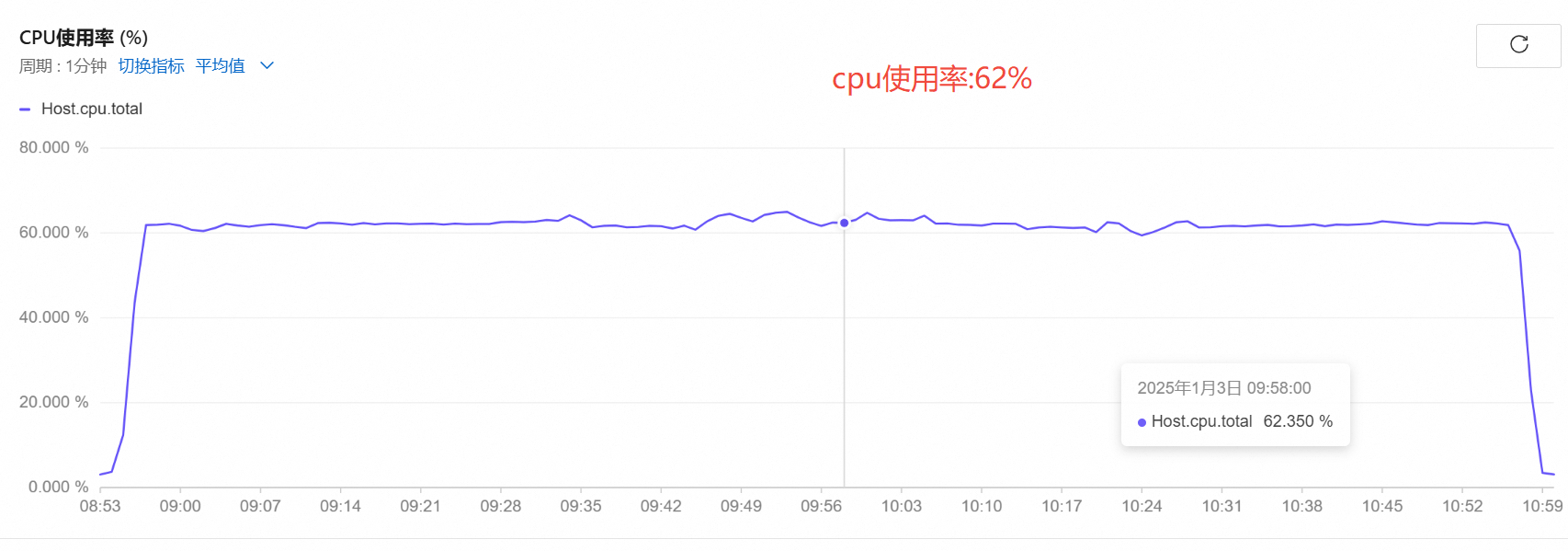
-
cpu负载
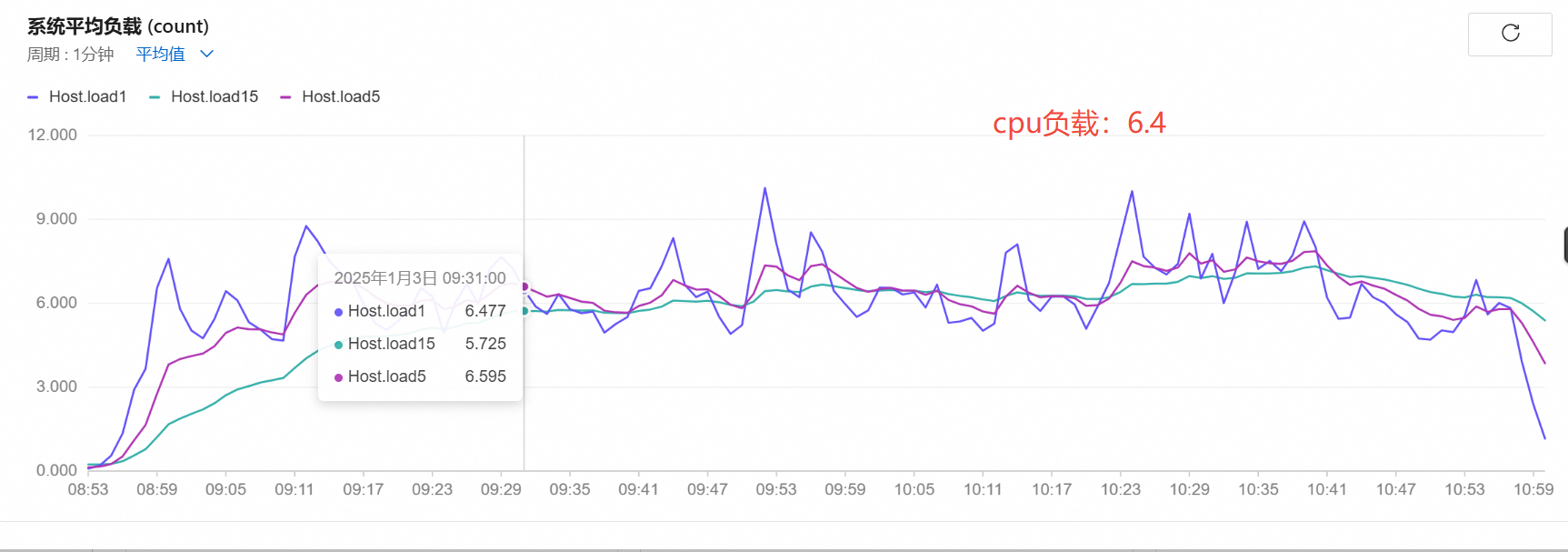
-
内存使用率
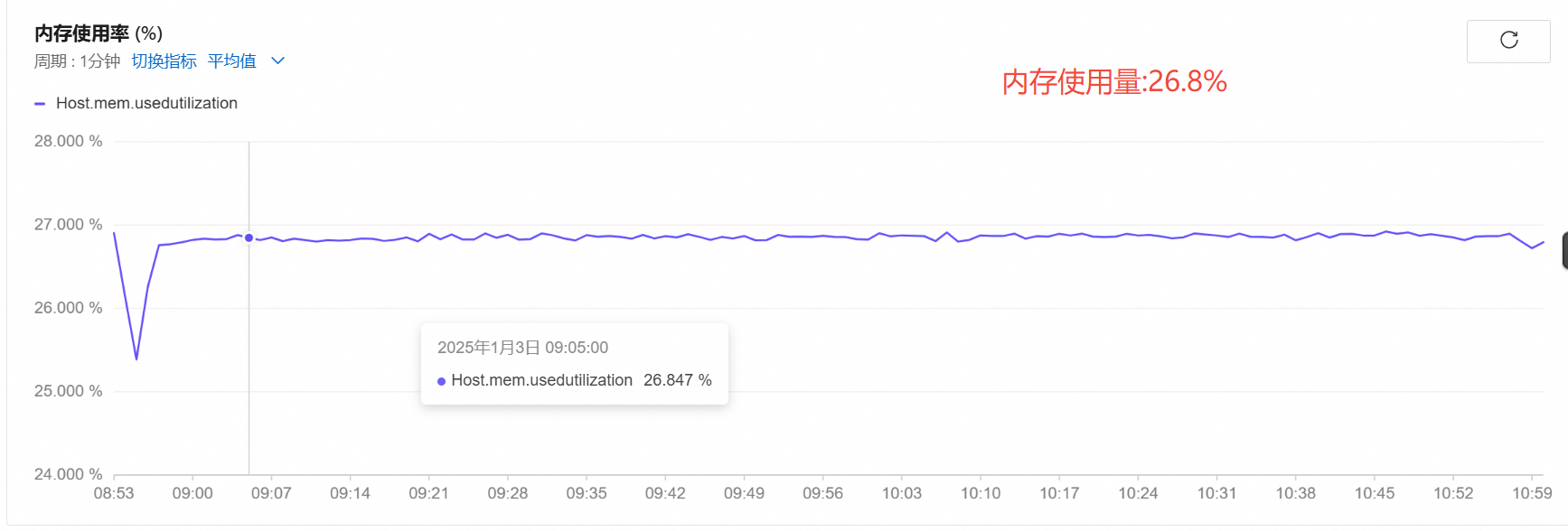
-
带宽:
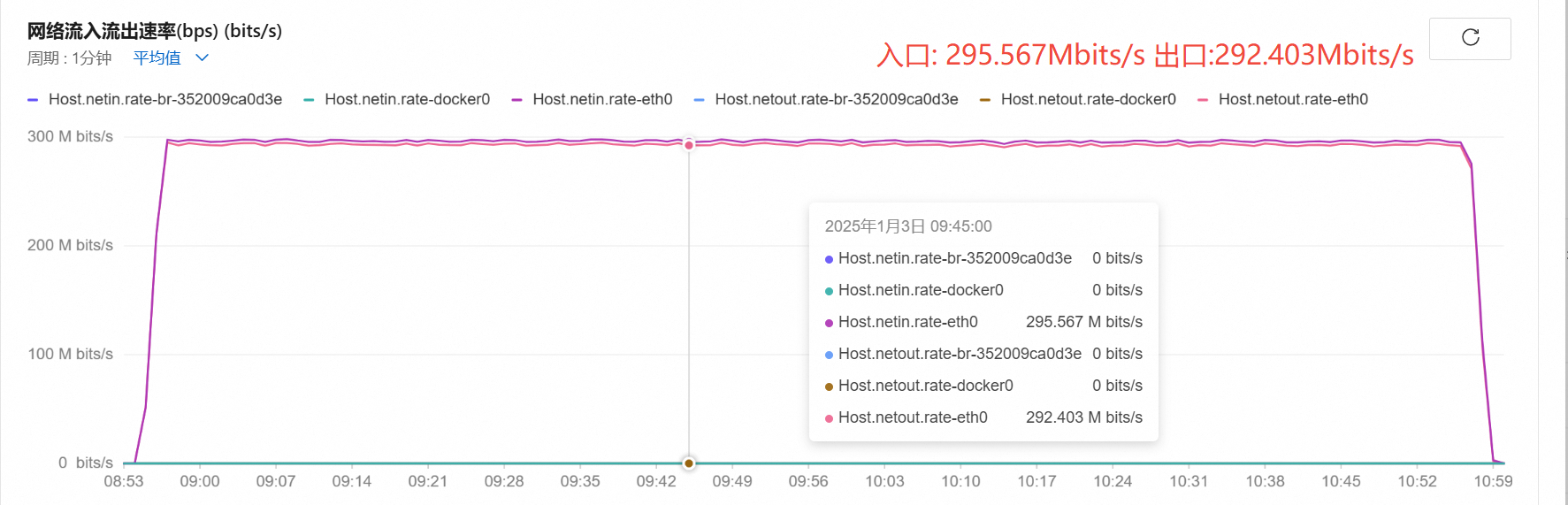
-
通话量:
-
内存增长:
opensips:959.4MiB->990.4MiB=31MiB | rtpengine: 23.89MiB->123.1MiB=99.21MiB
通过对比:1600-1700路和1700-1800路的带宽增长情况,发现1700路->1800路的带宽增长迟缓,没有达到理论值。
所以,8C8G压测的极限是1700路,此极限是rtpengine的极限,推测:cpu负载大,导致rtpengine出流较慢,udp数据包减少,影响了通话质量。opensips其实并未到极限。
压测结束后,通过opensips-cli执行mi get_statistics all
能够看到实际占用的内存很少,还有大量的内存空闲。
|
|
sip 使用tcp通信
场景:
uac–tcp—->opensips—-tcp—->uas
-
1600路
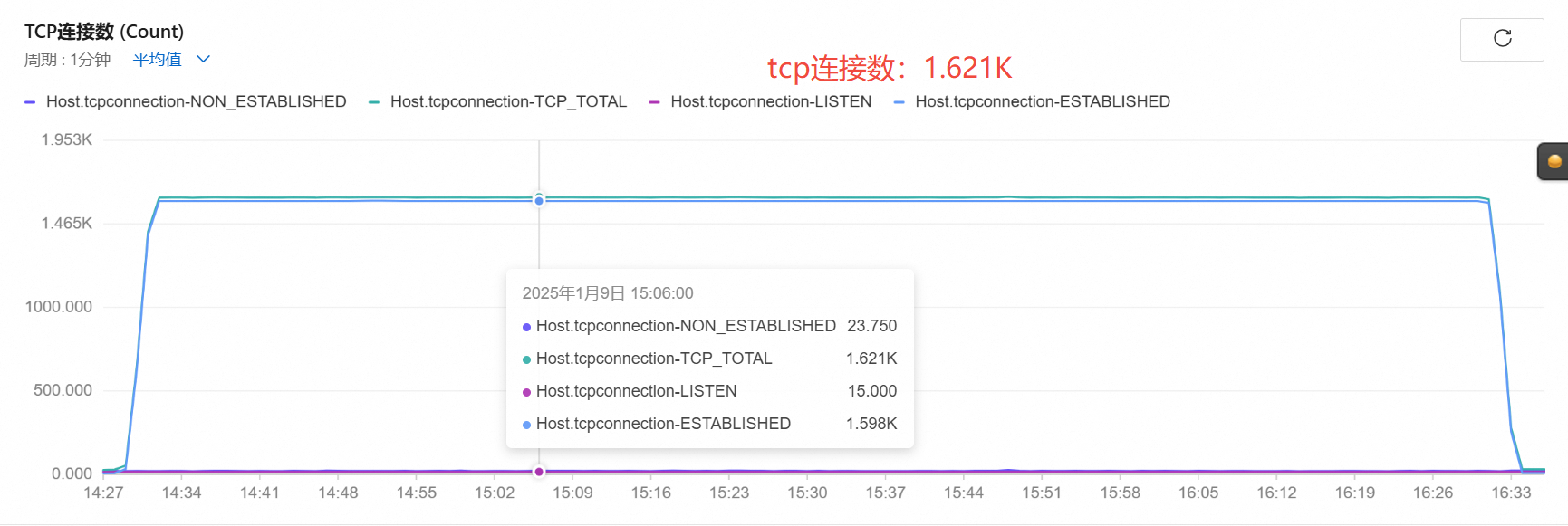
-
1800路
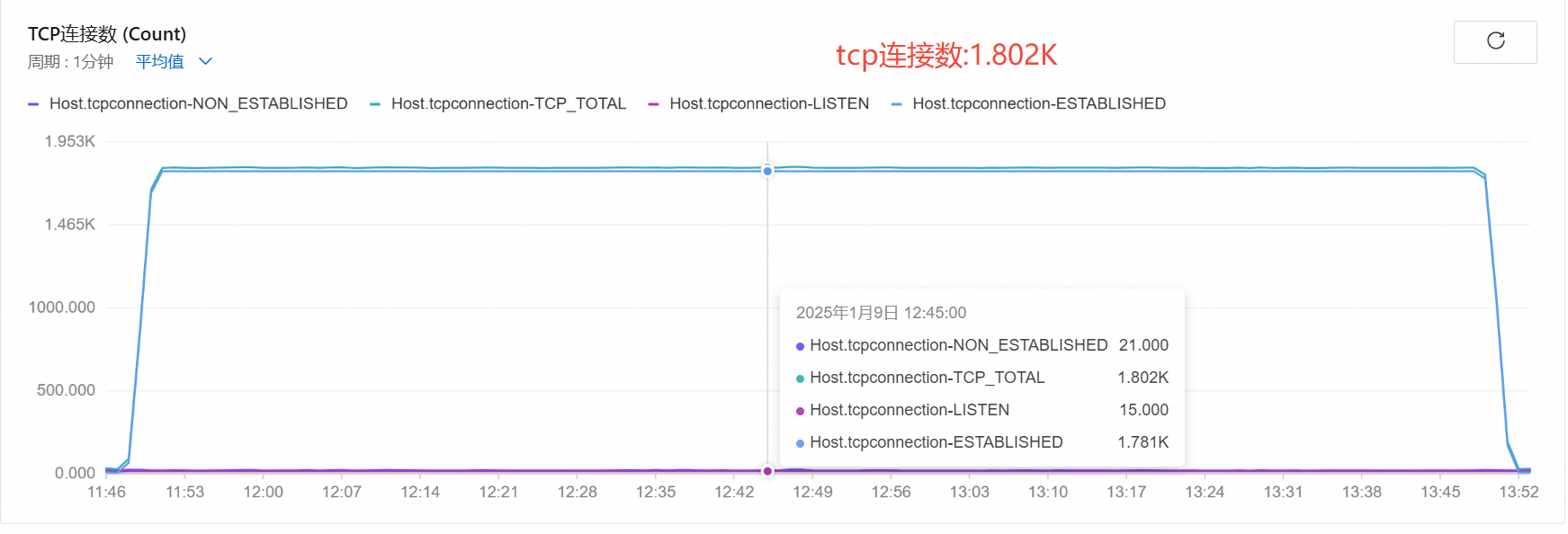
- uac和opensips使用tcp通信,uac是多个tcp连接到opensips的同一个端口.
- 在opensips和uas使用tcp通信时,原本以为会是多个tcp和uas连接,结果只用了一个tcp连接,所有的请求都是复用这个tcp连接。
- tcp的性能比udp性能要高,tcp连接方式并发能到1800路。
总结
- opensips-cli只能获取实时数据,无法获取历史数据。可以考虑使用opensips-cp监控。
- rtpengine在高并发情况下,为啥会出流慢,目前还未找到原因,rtpengine的日志也没有报错。